가상 면접 사례로 배우는 대규모 시스템 설계 기초 1장 내용을 정리한 글입니다.
개요
한 명의 사용자를 지원하는 시스템에서 출발하여 단계적으로 몇 백만 사용자를 지원하는 시스템을 설계한다.
단일 서버
- 모든 컴포넌트가 단 한 대의 서버에서 실행되는 간단한 시스템
- 웹 앱, 데이터베이스, 캐시 등이 전부 한대에서 실행된다.
- 사용자의 요청은 DNS를 통해 ip 주소를 얻어낸 후 전달된다.
데이터베이스 분리
- 웹 서버 계층과 데이터베이스 서버 계층을 독립적으로 확장할 수 있게 된다.
수직적 확장(Scale Up) vs 수평적 확장(Scale Out)
- 수직적 확장
- CPU, RAM 등 서버 성능을 업그레이드 하는 것을 의미한다.
- 서버 성능을 업그레이드하는 데에는 물리적, 비용적 한계가 있다.
- 장애에 대한 복구, 다중화 방안이 없다.
- 수평적 확장은 서버 개수를 추가하는 것이다.
- 위의 수직적 확장의 단점들 때문에 수평적 확장이 대규모 어플리케이션에 적합하다.
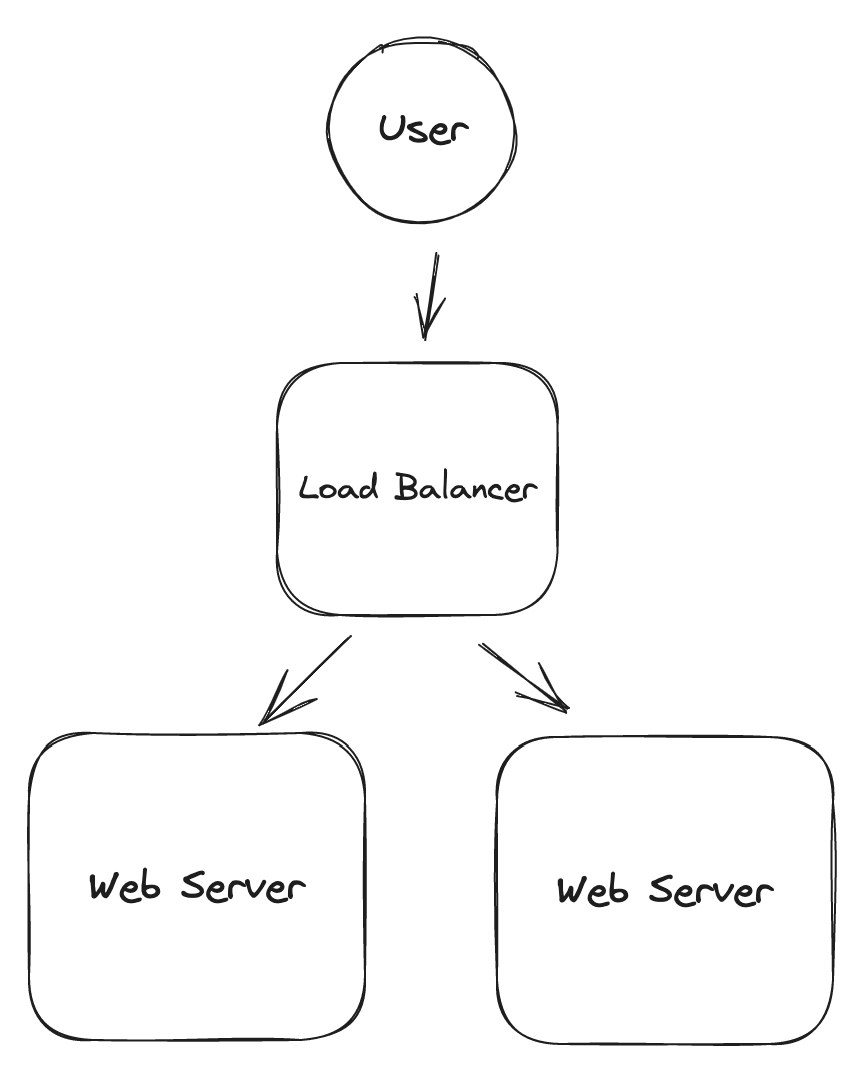
로드밸런서
- 수평적 확장을 통해 웹 서버를 여러 대 두게 되면, 각 서버에 대한 연결을 위해 로드 밸런서를 이용해야 한다.
- 서버 1이 다운되면 모든 트래픽은 서버2로 전송된다.
- ASG(Auto Scaling Group) 등을 이용해 트래픽에 유연하게 대비할 수 있다.
데이터베이스 다중화

- 웹 서버가 아닌 데이터베이스 서버에도 장애가 발생할 수 있다. 이를 해결하기 위해 데이터베이스를 다중화 한다.
- master - slave 관계를 설정하고 원본은 master 서버, 사본은 slave 서버에 저장한다.
- 쓰기 연산은 master 에서만 지원하고 slave는 읽기 연산만 지원한다.
- 대부분의 애플리케이션은 읽기 연산의 비중이 훨씬 높기 때문이다.
- 성능, 안정성, 가용성을 챙길 수 있다.
- 가용성
- 만약 한 대뿐인 slave 서버에 장애가 발생한다면, 일시적으로 모든 연산을 master 서버에서 처리하고 새로운 slave 서버를 생성하여 장애가 발생한 서버를 대체한다.
- 만약 master 서버에 장애가 발생한다면, 한 대의 slave 서버가 master 가 되고, 새로운 slave 서버를 추가한다.
- slave 데이터 서버에 저장된 데이터가 최신이 아닐 수 있다.
- 복구 script를 돌려 추가해주어야 한다.
- 다중 마스터, 원형 다중화 방식을 고려할 수도 있다.
- slave 데이터 서버에 저장된 데이터가 최신이 아닐 수 있다.
캐시
- 값 비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청을 보다 빨리 처리하기 위한 저장소
- 별도의 캐시 계층을 두면 규모를 독립적으로 확장할 수 있다.
- 읽기 주도형 캐시 전략
- 값이 캐시에 있으면 캐시에서 반환
- 없으면 DB에서 읽어서 캐시에 쓰고 반환
- 유의점
- 휘발성 메모리임에 유의해야 한다.
- 만료 정책을 마련해야 한다. 너무 짧으면 miss가 많아지고, 길면 원본과 차이가 날 수 있다.
- 일관성 유지
- 페이스북 Scaling Memcache at Facebook 참조
- Single Point of Failure에 대비해 캐시 서버를 분산해야 한다.
- 경우에 따라 Redis 실패 시 -> local 메모리 캐시 사용도 괜찮은 것 같다.
- 캐시 메모리 과할당
- 캐시 메모리가 너무 작아 성능이 떨어지는 경우나 데이터가 갑자기 늘어날 경우에 대비하여 메모리를 과할당할 수 있다.
- 캐시 데이터 방출 정책
- 메모리가 꽉 찼을 때 내보낼 데이터를 정하는 정책
- LRU, LFU, FIFO 등
CDN
- 정적 컨텐츠 제공
- 지리적으로 가장 가까운 CDN 서버가 정적 컨텐츠를 제공한다.
- 보통 Third-party 제공자에 의해 운영되므로 이에 대한 비용이 발생한다.
- CDN 장애 시 동작 시나리오를 마련해두어야 한다.
- 일시적으로 원본 서버에서 정적 컨텐츠를 가져와 제공
Stateless 웹 계층
- 웹 계층을 수평적으로 확장하기 위해서는 상태 정보를 제거해야 한다.
- NoSQL이나 관계형 데이터베이스 같은 지속성 저장소에 상태 정보를 저장하면 좋다.
데이터 센터
- 여러 개의 데이터 센터를 이용하는 사례이다.
- 장애가 없는 경우 GeoDNS(지리적 라우팅)을 이용해 가장 가까운 데이터 센터로 라우팅 된다.
- 데이터 동기화 문제
- 데이터 센터마다 별도의 DB를 사용 중이라면 failover 시 데이터가 손실 될 수 있다.
- 넷플릭스 Active-Active for Multi-Reginonal Resiliency 참조
메시지 큐

- 메시지의 무손실을 보장하고, 비동기 통신을 지원하는 컴포넌트다.
- 메시지 큐를 사용하면 서비스 또는 서버 간 결합이 느슨해져 안정적인 확장이 가능하다.
- 생산자는 소비자에 장애가 발생해도 메시지를 발행할 수 있다.
- 소비자는 생산자에 장애가 발생해도 메시지를 수신할 수 있다.
로그, 메트릭과 자동화
- 사업 규모가 커지고 나면, 이런 도구들에 필수적으로 투자해야 한다.
- 로그
- 시스템의 오류와 문제를 쉽게 찾으려면 에러 로그를 모니터링 해야 한다.
- 메트릭
- 사업 현황에 유용한 정보를 얻을 수 있다.
- daily active user, 재방문, 성능 모니터링
- 사업 현황에 유용한 정보를 얻을 수 있다.
- 자동화
- 생산성을 높이기 위한 도구 활용
- CI, CD 등
데이터 베이스 규모 확장
- 수직적 확장
- 고성능 자원 증설
- 스택 오버플로우는 2013년 한 해 천만명의 사용자를 한 대의 마스터 사용했다고 한다.
- 증설 한계, 비용, Single Point of Failure
- 수평적 확장
- 샤딩
- 데이터 베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술이다.
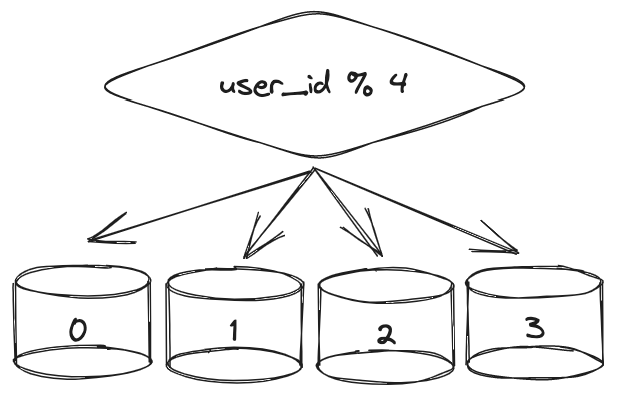
- 데이터 베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술이다.
- 샤딩
- 샤딩 시 고려할 사항
- 데이터의 재 샤딩(resharding)
- 데이터가 너무 많아져서 하나의 샤드가 데이터를 더 이상 감당하기 힘들 때
- 샤드 간 분포가 균등하지 못하여 공간 소모가 불균형하게 일어날 때
- 5장에서 배울 안정 해시를 이용해 해결한다.
- 셀럽 문제
- 특정 샤드에 쿼리가 집중되어 서버에 과부하가 생기는 문제
- 저스틴 비버, 레이디 가가 등 셀럽의 정보가 담긴 샤드에 쿼리가 집중될 수 있음
- 조인과 비정규화 문제
- 샤드 적용 시 여러 샤드에 걸친 데이터를 조인하기 힘들어진다.
- 비정규화를 통해 조인 없이 쿼리가 수행될 수 있도록 할 수 있다.
- 데이터의 재 샤딩(resharding)
- NoSQL의 다양한 활용 사례 참조